
On the Edge of Innovation: The Web’s Evolution From Serverless to Edge Computing


An Intro to Cloud, Serverless, and Edge Computing
Web developers have been enjoying a technological renaissance over the past couple of decades. The field of cloud computing began as a way to host web applications on a global scale and has since allowed developers to only pay for the computing resources they consume. The evolution of cloud computing then led to the creation of serverless computing in the 2010s, which removed the burden of managing infrastructure off the shoulders of busy developers. Serverless computing had other benefits too, like automatic scaling, faster deployments, and a cheaper cost. An example of the utility of serverless computing is Cloudflare Workers, which enable web developers to split up their applications into smaller components that run on demand. Rather than burning computing resources by keeping a large application running constantly on the cloud, developers can split an application into separate functions that quickly spin up from a dormant state to return a request.
Though serverless functions quickly activate to return a request, the geographical distance between the client machine making the request and the server returning the response can cause excessive latency. For example, if web developers in New York want to create a highly responsive API for their clients in Singapore, they may not want a centralized server in the U.S. to process their client’s requests. Edge computing is the evolution of serverless computing that brings the benefits of serverless computing closer to the end user. Edge computing enables blazingly fast, highly available, personalized web applications.
Serverless Computing
It’s necessary to understand how serverless computing works to understand how it differs from edge computing. I created a simple diagram of how serverless computing differs from traditional cloud computing:
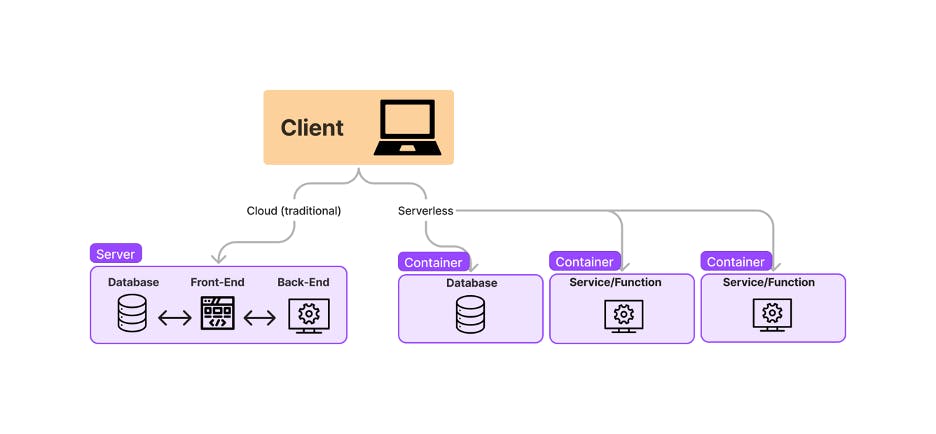
Notice that in traditional cloud computing, the client sends a request to a server that has the database, front end, and back end of the application bundled together. These separate parts of the application communicate with one another to return a response to the client. Even though a client may only need to access a specific part of the application, like an ordering service, the whole server must be kept awake to process the request. Allowing the server to sleep risks a very slow start-up time every time a client makes a request. However, it’s a costly and wasteful solution to keep a server running constantly when it’s not being used.
In serverless computing, the client’s request is routed to exactly where it’s needed. The separation of services or functions allows for a rapid initialization time for each one. These services are run on lightweight containers that may be hosted on different servers, and they stay dormant until a request or event triggers them to awaken. Innovation in programming languages like JavaScript’s lightweight V8 engine has contributed to lightweight runtimes that contribute to even faster application start-up times.
Web Applications in the Serverless Era
Serverless computing has enabled web developers to create scalable, decoupled web applications and focus on code rather than infrastructure. Web applications can be decoupled into services, functions, and databases hosted on separate, lightweight containers. Imagine an e-commerce website with a containerized ordering service that can start on demand whenever a purchase is made. Similarly, the application’s database doesn’t have to be constantly running, and can also start up when a new customer registers or a purchase is made. If the website hosts a popular promotion, a cloud provider can scale the application automatically by initializing new instances of a particular service.
Imagine accessing our serverless e-commerce application from the user's perspective. Upon accessing the site, the user is instantly served a cached webpage by a Content Delivery Network (CDN), which is a server that serves cached content from as close to the user as possible. When the user tries to log in, a containerized authorization service is instantiated within milliseconds to provide an access token for the user to access their account. A promotions service notices that the user logged in and offers a personalized coupon for use in the store. When the user checks out, an ordering service starts up, passes the user’s order information to a payment processor’s API, and returns the successful payment message to the user.
Pitfalls of Serverless
Serverless computing is not a panacea for web developers. Like any architectural style, there are trade-offs to consider before using it. One such tradeoff is the issue of start times. Serverless functions need to start up quickly once they receive a request, but certain programming languages are more optimized for this than others. For example, C# cold start times can be twice as slow as JavaScript start times. As demonstrated in the linked article, start times vary dramatically depending on certain factors, such as the size of an application’s dependencies.
Another drawback to serverless computing is the complexity in make a stateful application stateless. A stateful application stores a user’s session information on a server and uses this information for future requests. In contrast, a stateless application relies on a database to store a user’s session information rather than the server. Stateless applications are a natural fit for serverless computing because the serverless model often uses different servers for different services or functions. However, a stateful application may have long workflows and processes relying on session information that would require a significant number of database requests within a serverless architecture. It would also require intensive development work to refactor long workflows to use a database rather than the server for session storage.
Edge Computing: The Evolution of Serverless
For some applications, the time it takes to send information to a cloud provider and get a response may be critically important. For example, imagine a stock trader using a real-time API to make trading decisions. It’s imperative for the API to both return a response and do so immediately. The user’s request also needs to be routed to a server as close to the end user as possible. Edge computing can benefit applications like these that require high availability, personalization, and low latency.
Edge computing shares a similar architecture to serverless computing, but with the overall goal of processing and storing data closer to end users. I created a simple diagram to illustrate how edge computing differs from serverless computing:
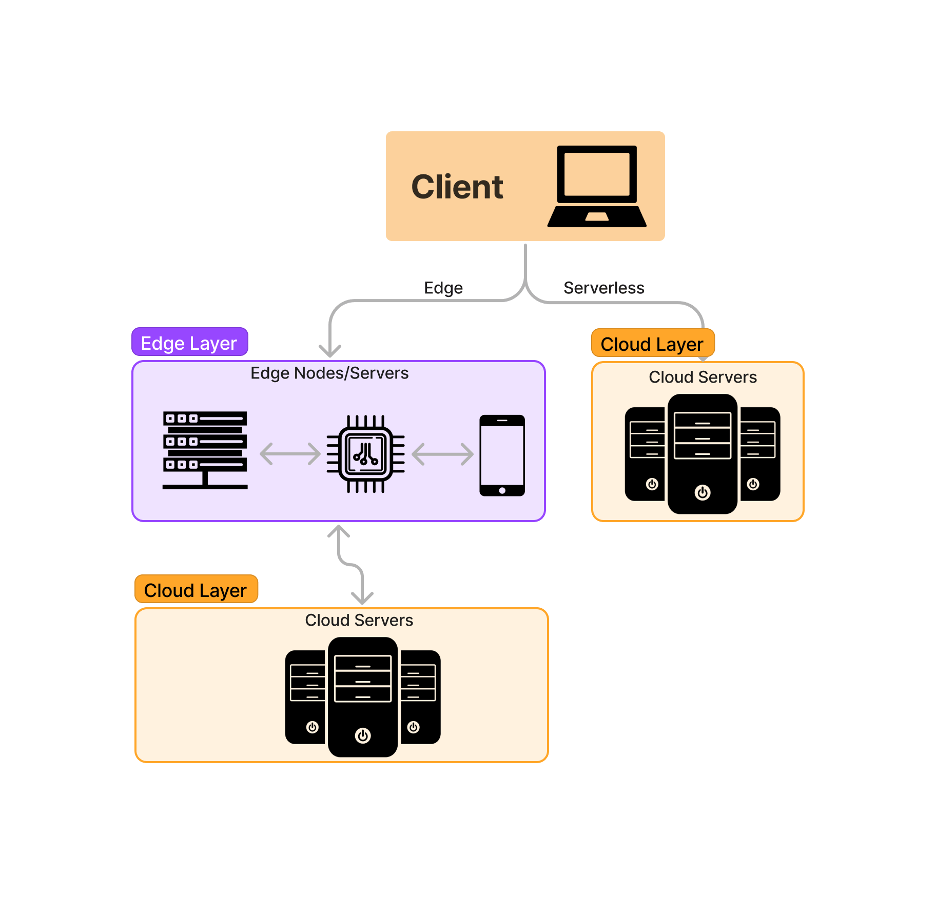
One way that edge computing builds on serverless computing is its use of edge servers and edge nodes. Edge servers are servers that are geographically closer to the end user than cloud servers. They provide computation and storage to reduce the computation needed at the more expensive and geographically farther cloud server level. Essentially, edge servers provide lower latency at a cheaper cost. Edge nodes are a more generic term for devices reducing the computation and storage burden at the cloud level like edge servers, but they can include IoT devices like a sensor or cellphone. Notice in the diagram that there are double arrows between edge nodes, edge servers, and cloud servers. Edge computing can be thought of as a fabric of systems communicating with one another.
Serverless Web Applications in the Edge Era
Edge computing provides new architectural, performance, and personalization choices for serverless web applications. For example, edge servers allow for more web content to be rendered on the server without worries about high server latency. Moving client-side rendered code to the server also improves a web application’s Core Web Vitals and subsequently its SEO performance. Because of edge computing, developers can be more strategic about what code is rendered on the server versus the client. Using Netlify’s edge functions with Next.js, developers can choose to selectively render server-side code (as granularly as individual components) using a lightweight runtime and enjoy even faster render times than with serverless functions. As a result, a user with a slow connection will see a page dynamically hydrate rather than a blank page as the server responds to their request.
New opportunities for personalization are another benefit of edge computing. This is because edge computing brings the relationship between infrastructure and code closer than ever before. Using edge middleware, web developers can execute server-side logic on the edge before a user’s request is processed on the web application. Developers can abstract out modules or functions from their application to be used as middleware. Authentication is a good example of where this can be used. Middleware code handling authentication can immediately redirect a user attempting to access a forbidden page even before the request is received by the web application. Another benefit of middleware is that abstracted code can be easily reused in other applications, creating a composable and fast way to architect web applications. Because of edge middleware, web applications on the edge can enjoy the speed of server-side rendered code with the interactivity and personalization benefits of code rendered on the client.
Pitfalls of Edge Computing in Serverless Applications
There are tradeoffs like consistency and complexity to consider before incorporating edge computing into a serverless application. As for complexity, an application using edge computing may involve managing extra hardware, like edge servers and edge nodes. Additionally, web developers may have to write additional code to manage the processing and storage of data in the extra hardware. The added architectural complexity also adds more areas where a technical failure could occur.
Consistency is also a concern with edge computing. Applications that require strong consistency may struggle to keep the data between multiple edge servers and nodes in sync while maintaining high availability. Applications that only require eventual consistency are a better fit for edge computing.
The Benefits of Serverless at the Edge
Edge computing should be viewed as an evolution of serverless computing architecture rather than a replacement. Both serverless and edge applications provide latency, cost, scalability, and availability benefits compared to a monolithic application hosted in the cloud. Web developers should consider whether the benefits of edge computing are worth integrating into their serverless applications. A serverless application that needs to optimize for personalization, extremely low latency, or low cloud server costs may benefit from exploring edge computing. Between serverless and edge computing, web developers have never had more flexibility to create a better user and developer experience.
I hope you learned a lot about serverless and edge computing! Feel free to follow me on Hashnode and Twitter for more of my writing (@jahabeebs)
Credits: “Laptop” by Supeni from Noun Project “Database” by amy morgan from Noun Project “Front End” by M. Oki Orlando from Noun Project “Back End” by Ary Prasetyo from Noun Project “Chip” by Maxim Kulikov from Noun Project “Phone” by Anthony Arteaga from Noun Project “Server” by nugra from Noun Project “Server” by b farias from Noun Project